📚 Taxonomy of Quality Issues
We establish a unified taxonomy encompassing two core dimensions: Generated Code Quality Issues and Training Data Quality Issues.
💻 RQ1: Generated Code Quality Issues
We categorize quality issues in LLM-generated code into 9 core dimensions:
| Dimension | Description | Typical Manifestations |
|---|---|---|
| Correctness | Functional accuracy and executability | Syntax errors, logical flaws, API misuse |
| Security | Resilience against malicious exploitation | Inherent design flaws, external vulnerabilities |
| Compliance | Adherence to legal, ethical, and safety standards | Copyright infringement, privacy leakage, malicious code |
| Robustness | Ability to handle abnormal inputs gracefully | Inadequate error handling, boundary condition failures |
| Maintainability | Ease of long-term code modification | Disorganized structure, low reusability |
| Understandability | Human-readability and clarity | Poor naming conventions, lack of documentation |
| Efficiency | Optimal system resource utilization | Suboptimal time complexity, improper memory management |
| Parsimony | Conciseness of generated results | Redundant logic, useless loops, extreme verbosity |
| Miscellaneous | Anomalies outside core dimensions | Instruction-following failures |

Fig. 3. Taxonomy of Generated Code Quality Issues
📄 Referenced Papers
LLMs Meet Library Evolution
LLMs Meet Library Evolution: Evaluating Deprecated API Usage in LLM-based Code Completion
Copilot Security
Is GitHub’s Copilot as Bad as Humans at Introducing Vulnerabilities in Code?
Copilot Evaluation
An Empirical Evaluation of GitHub Copilot’s Code Suggestions
HalluCode
Exploring and Evaluating Hallucinations in LLM-Powered Code Generation
CodeHalu
CodeHalu: Investigating Code Hallucinations in LLMs via Execution-based Verification
EffiBench
EffiBench: Benchmarking the Efficiency of Automatically Generated Code
Mercury
Mercury: A Code Efficiency Benchmark for Code Large Language Models
SStuBs
Large Language Models and Simple, Stupid Bugs
package hallucinations
We Have a Package for You! A Comprehensive Analysis of Package Hallucinations by Code Generating LLMs
HallTrigger
Code Hallucination
Large Language Models for Code
Large Language Models for Code: Security Hardening and Adversarial Testing
Purple Llama CYBERSECEVAL
Purple Llama CYBERSECEVAL: A Secure Coding Benchmark for Language Models
Lost at C
Lost at C: A User Study on the Security Implications of Large Language Model Code Assistants
AI Assistants Security
Do Users Write More Insecure Code with AI Assistants?
The Counterfeit Conundrum
The Counterfeit Conundrum: Can Code Language Models Grasp the Nuances of Their Incorrect Generations?
Bugs in LLM-generated Code
Bugs in Large Language Models Generated Code: An Empirical Stud
GitHub Copilot, Amazon CodeWhisperer, ChatGPT
Evaluating the Code Quality of AI-Assisted Code Generation Tools: An Empirical Study on GitHub Copilot, Amazon CodeWhisperer, and ChatGPT
ChatGPT Code Quality
No Need to Lift a Finger Anymore? Assessing the Quality of Code Generation by ChatGPT
CloudAPIBench
On Mitigating Code LLM Hallucinations with API Documentation
CodeMirage
CodeMirage: Hallucinations in Code Generated by Large Language Models
LLM-generated Code Efficiency
On Evaluating the Efficiency of Source Code Generated by LLMs
AutoAPIEval
A Comprehensive Framework for Evaluating API-oriented Code Generation in Large Language Models
DeSec
Decoding Secret Memorization in Code LLMs Through Token-Level Characterization
When Fine-Tuning LLMs Meets Data Privacy
When Fine-Tuning LLMs Meets Data Privacy: An Empirical Study of Federated Learning in LLM-Based Program Repair
Bias Unveiled
Bias Unveiled: Investigating Social Bias in LLM-Generated Code
FairCoder
FairCoder: Evaluating Social Bias of LLMs in Code Generation
CodeIP
CodeIP: A Grammar-Guided Multi-Bit Watermark for Large Language Models of Code
From Effectiveness to Efficiency
From Effectiveness to Efficiency: Comparative Evaluation of Code Generated by LCGMs for Bilingual Programming Questions
ENAMEL
How Efficient is LLM-Generated Code? A Rigorous & High-Standard Benchmark
DeVAIC
DeVAIC: A Tool for Security Assessment of AI-generated Code
PTMs
Comparing Robustness Against Adversarial Attacks in Code Generation: LLM-Generated vs. Human-Written
Software Librarian
Is ChatGPT a Good Software Librarian? An Exploratory Study on the Use of ChatGPT for Software Library Recommendations
Codequal Analyzer
Improving LLM-Generated Code Quality with GRPO
Artificial-Intelligence Generated Code Considered Harmful
Artificial-Intelligence Generated Code Considered Harmful: A Road Map for Secure and High-Quality Code Generation
Unveiling Inefficiencies in LLM-Generated Code
Unveiling Inefficiencies in LLM-Generated Code: Toward a Comprehensive Taxonomy
Python Tests Quality
Quality Assessment of Python Tests Generated by Large Language Models
CoQuIR
CoQuIR: A Comprehensive Benchmark for Code Quality-Aware Information Retrieval
REAL
Training Language Models to Generate Quality Code with Program Analysis Feedback
CIDRe
CIDRe: A Reference-Free Multi-Aspect Criterion for Code Comment Quality Measurement
Infinite-Instruct
Infinite-Instruct: Synthesizing Scaling Code instruction Data with Bidirectional Synthesis and Static Verification
Quality In, Quality Out
Quality In, Quality Out: Investigating Training Data's Role in AI Code Generation
Security and Quality in LLM-Generated Code
Security and Quality in LLM-Generated Code: A Multi-Language, Multi-Model Analysis
SwallowCode
Rewriting Pre-Training Data Boosts LLM Performance in Math and Code
ROSE
ROSE: Transformer-Based Refactoring Recommendation for Architectural Smells
Refining ChatGPT-Generated Code
Refining ChatGPT-Generated Code: Characterizing and Mitigating Code Quality Issues
ReCode
ReCode: Updating Code API Knowledge with Reinforcement Learning
Seed-Coder
Seed-Coder: Let the Code Model Curate Data for Itself
Data-efficient Fine-tuning
Data-efficient LLM Fine-tuning for Code Generation
CRPE
CRPE: Expanding The Reasoning Capability of Large Language Model for Code Generation
DeepSeek-Coder
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
CodeSmellEval
How Propense Are Large Language Models at Producing Code Smells? A Benchmarking Study
RPG
Rethinking Repetition Problems of LLMs in Code Generation
Repetition In Repetition Out
Repetition In Repetition Out: Towards Understanding Neural Text Degeneration from the Data Perspective
Beyond Correctness
Beyond Correctness: Benchmarking Multi-dimensional Code Generation for Large Language Models
Generated Code Diversity
Is Functional Correctness Enough to Evaluate Code Language Models? Exploring Diversity of Generated Codes
CodeMI
Does Your Neural Code Completion Model Use My Code? A Membership Inference Approach
CodeCipher
CodeCipher: Learning to Obfuscate Source Code Against LLMs
Code Llama
Code Llama: Open Foundation Models for Code
Codex
Evaluating Large Language Models Trained on Code
Path Planning Evaluation
Assessing LLM code generation quality through path planning tasks
CODEJUDGE
CODEJUDGE : Evaluating Code Generation with Large Language Models
Synthetic Data Generation
Synthetic Data Generation Using Large Language Models: Advances in Text and Code
Unseen Horizons
Unseen Horizons: Unveiling the Real Capability of LLM Code Generation Beyond the Familiar
Code Generation Survey
A Survey on Large Language Models for Code Generation
DataRecipe
DataRecipe --- How to Cook the Data for CodeLLM?
aiXcoder-7B
aiXcoder-7B: A Lightweight and Effective Large Language Model for Code Processing
Imperfect Code Generation
Imperfect Code Generation: Uncovering Weaknesses in Automatic Code Generation by Large Language Models
ClassEval
Evaluating Large Language Models in Class-Level Code Generation
UCD-Training
Unseen-Codebases-Domain Data Synthesis and Training Based on Code Graphs
DRAINCODE
DRAINCODE: Stealthy Energy Consumption Attacks on Retrieval-Augmented Code Generation via Context PoisoningPreprint
RealSec-Bench
RealSec-bench: A Benchmark for Evaluating Secure Code Generation in Real-World Repositories
ShortCoder
ShortCoder: Knowledge-Augmented Syntax Optimization for Token-Efficient Code GenerationPreprint
APIKG4SYN
Framework-Aware Code Generation with API Knowledge Graph-Constructed Data: A Study on HarmonyOS
MultiCodeIF
A hierarchical and evolvable benchmark for fine-grained code instruction following with multi-turn feedback
Beyond Functional Correctness
Beyond functional correctness: Investigating coding style inconsistencies in large language models
Adadec
Adadec: Uncertainty-guided adaptive decoding for llm-based code generation
Code Copycat Conundrum
Code Copycat Conundrum: Demystifying Repetition in LLM-based Code Generation
AllianceCoder
What to retrieve for effective retrieval-augmented code generation? an empirical study and beyond
RustEvo^ 2
RustEvo^ 2: An Evolving Benchmark for API Evolution in LLM-based Rust Code Generation
RobGen
A Preliminary Study on the Robustness of Code Generation by Large Language Models
Llm Hallucinations in Practical Code Generation
Llm hallucinations in practical code generation: Phenomena, mechanism, and mitigation
COFFE
COFFE: A Code Efficiency Benchmark for Code Generation
AATK Benchmark
Asleep at the keyboard? assessing the security of github copilot's code contributions
📊 RQ2: Training Data Quality Issues
We categorize intrinsic flaws within pre-training and fine-tuning corpora:
1. Code Attribute Quality Issues
Inherent defects within individual code samples that models explicitly learn (correctness, security, etc.).
2. Non-Code Attribute Quality Issues
Non-code textual noise and macro-level dataset flaws:
- Compliance & Security: Illegal/harmful, copyright-infringing, privacy-leaking text.
- Distribution Imbalance: Skewed proportions across languages, domains, or types.
- Redundancy: Excessive repetition or synthetic data degradation.
- Diversity: Insufficient coverage of real-world scenarios.
- Contamination: Leakage of evaluation data into training sets.
- Low-Value Data: Meaningless text, format noise, low-information density.
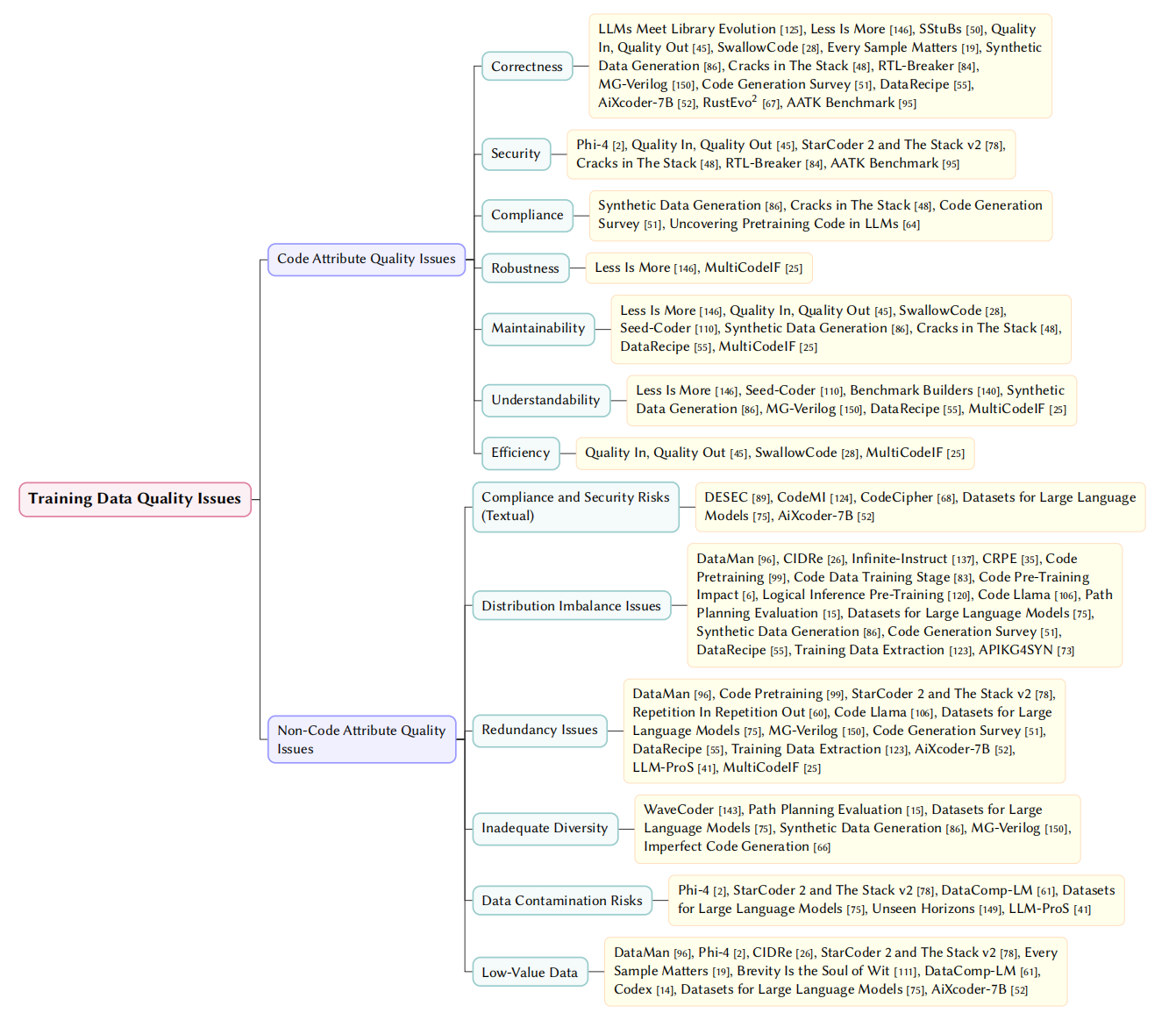
Fig. 4. Taxonomy of Training Data Quality Issues
📄 Referenced Papers
LLMs Meet Library Evolution
LLMs Meet Library Evolution: Evaluating Deprecated API Usage in LLM-based Code Completion
Less is More
Less is More: On the Importance of Data Quality for Unit Test Generation
DataMan
DataMan: Data Manager for Pre-training Large Language Models
Phi-4
Phi-4 Technical Report
SStuBs
Large Language Models and Simple, Stupid Bugs
DeSec
Decoding Secret Memorization in Code LLMs Through Token-Level Characterization
CIDRe
CIDRe: A Reference-Free Multi-Aspect Criterion for Code Comment Quality Measurement
Infinite-Instruct
Infinite-Instruct: Synthesizing Scaling Code instruction Data with Bidirectional Synthesis and Static Verification
Quality In, Quality Out
Quality In, Quality Out: Investigating Training Data's Role in AI Code Generation
SwallowCode
Rewriting Pre-Training Data Boosts LLM Performance in Math and Code
Seed-Coder
Seed-Coder: Let the Code Model Curate Data for Itself
CRPE
CRPE: Expanding The Reasoning Capability of Large Language Model for Code Generation
Code Pretraining
How Does Code Pretraining Affect Language Model Task Performance?
StarCoder 2 and The Stack v2
StarCoder 2 and The Stack v2: The Next Generation
Repetition In Repetition Out
Repetition In Repetition Out: Towards Understanding Neural Text Degeneration from the Data Perspective
Every Sample Matters
Every Sample Matters: Leveraging Mixture-of-Experts and High-Quality Data for Efficient and Accurate Code LLM
Code Data Training Stage
At Which Training Stage Does Code Data Help LLMs Reasoning?
WaveCoder
WaveCoder: Widespread And Versatile Enhancement For Code Large Language Models By Instruction Tuning
Brevity is the soul of wit
Brevity is the soul of wit: Pruning long files for code generation
Benchmark Builders
Large Language Models are Qualified Benchmark Builders: Rebuilding Pre-Training Datasets for Advancing Code Intelligence Tasks
CodeMI
Does Your Neural Code Completion Model Use My Code? A Membership Inference Approach
CodeCipher
CodeCipher: Learning to Obfuscate Source Code Against LLMs
Code Pre-training Impact
To Code, or Not To Code? Exploring Impact of Code in Pre-training
DataComp-LM
DataComp-LM: In search of the next generation of training sets for language models
Logical Inference Pre-training
Which Programming Language and What Features at Pre-training Stage Affect Downstream Logical Inference Performance?
Code Llama
Code Llama: Open Foundation Models for Code
Codex
Evaluating Large Language Models Trained on Code
Path Planning Evaluation
Assessing LLM code generation quality through path planning tasks
Datasets for Large Language Models
Datasets for Large Language Models: A Comprehensive Survey
Synthetic Data Generation
Synthetic Data Generation Using Large Language Models: Advances in Text and Code
Cracks in The Stack
Cracks in The Stack: Hidden Vulnerabilities and Licensing Risks in LLM Pre-Training Datasets
Unseen Horizons
Unseen Horizons: Unveiling the Real Capability of LLM Code Generation Beyond the Familiar
RTL-Breaker
RTL-Breaker: Assessing the Security of LLMs Against Backdoor Attacks on HDL Code Generation
MG-Verilog
MG-Verilog: Multi-grained Dataset Towards Enhanced LLM-assisted Verilog Generation
Code Generation Survey
A Survey on Large Language Models for Code Generation
DataRecipe
DataRecipe --- How to Cook the Data for CodeLLM?
Training Data Extraction
Understanding Privacy Risks of Large Language Models in Japanese Based on Training Data Extraction Attacks
aiXcoder-7B
aiXcoder-7B: A Lightweight and Effective Large Language Model for Code Processing
Imperfect Code Generation
Imperfect Code Generation: Uncovering Weaknesses in Automatic Code Generation by Large Language Models
LLM-ProS
LLM-ProS: Analyzing Large Language Models’ Performance in Competitive Problem Solving
Uncovering Pretraining Code in LLMs
Uncovering Pretraining Code in LLMs: A Syntax-Aware Attribution Approach
APIKG4SYN
Framework-Aware Code Generation with API Knowledge Graph-Constructed Data: A Study on HarmonyOS
MultiCodeIF
A hierarchical and evolvable benchmark for fine-grained code instruction following with multi-turn feedback
RustEvo^ 2
RustEvo^ 2: An Evolving Benchmark for API Evolution in LLM-based Rust Code Generation
AATK Benchmark
Asleep at the keyboard? assessing the security of github copilot's code contributions