🔍 RQ4: Detection Methods
Detection techniques are evolving from rigid static analysis to dynamic, model-driven, and hybrid evaluation frameworks. They form the diagnostic foundation of LLM quality governance.
💻 1. Code-Level Detection
Identifies defects in generated code using three main paradigms:
- Dynamic Analysis: Test-based execution and runtime monitoring to assess accuracy and efficiency.
- Static Analysis: Rule-based detection (SonarQube, Semgrep) for syntax errors and vulnerabilities.
- Model-based Detection: “LLM-as-a-judge” techniques and ML classifiers for semantic filtering.
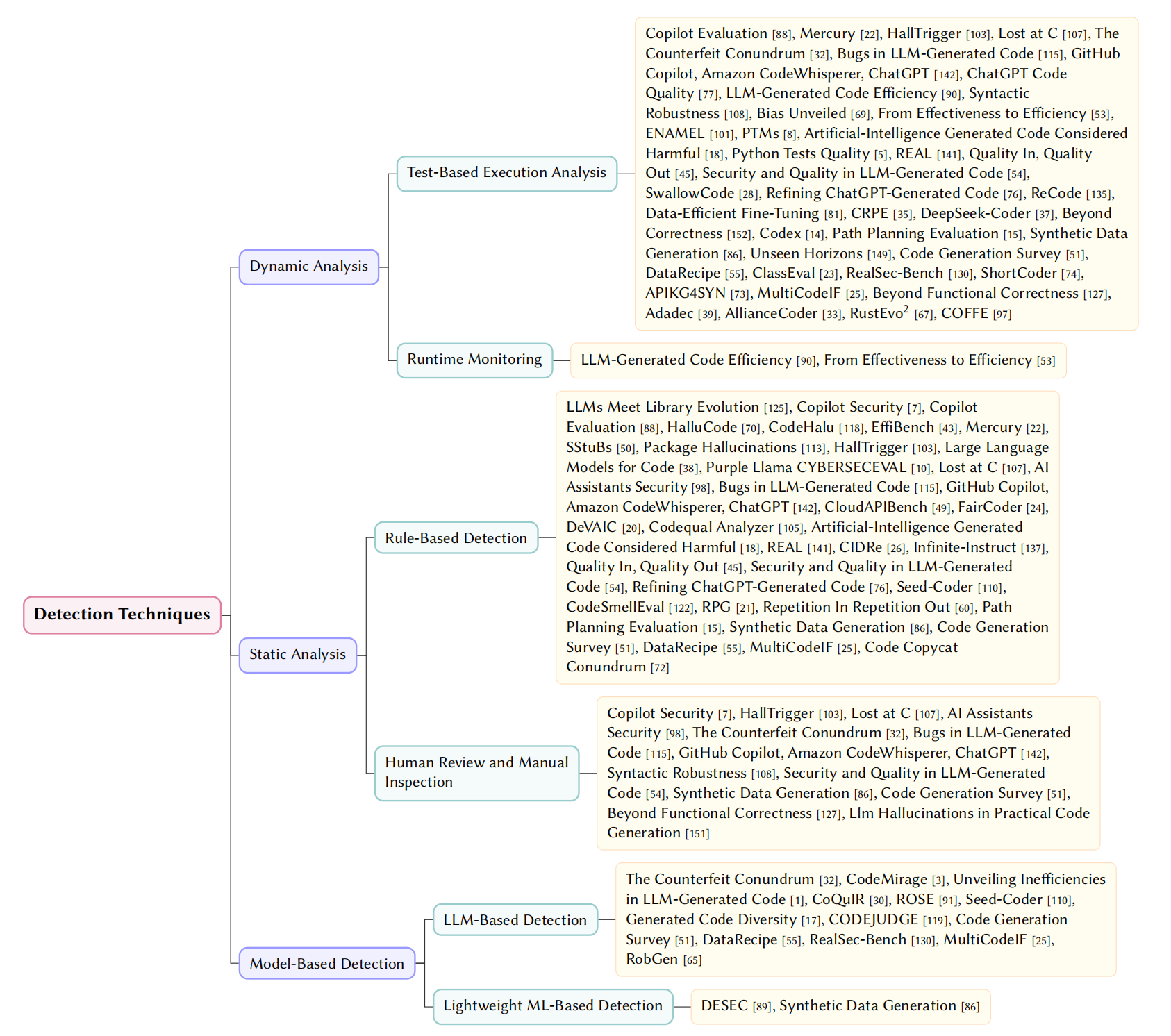
Fig. 6. Taxonomy of Code Issue Detection Techniques
📊 2. Data-Level Detection
Targets the integrity, provenance, and representativeness of training data:
- Dynamic Analysis: Execution-based validation and metric drift monitoring (detecting data leakage).
- Static Analysis: Rule-based detection and provenance tracing using file hashes.
- Model-based Detection: Semantic screening using LLMs to evaluate readability and hazards.

Fig. 7. Taxonomy of Training Data Issue Detection Techniques
📄 Referenced Papers
LLMs Meet Library Evolution
LLMs Meet Library Evolution: Evaluating Deprecated API Usage in LLM-based Code Completion
Less is More
Less is More: On the Importance of Data Quality for Unit Test Generation
Qwen
Qwen Technical Report
Qwen2
Qwen2 Technical Report
DataMan
DataMan: Data Manager for Pre-training Large Language Models
Phi-4
Phi-4 Technical Report
Copilot Security
Is GitHub’s Copilot as Bad as Humans at Introducing Vulnerabilities in Code?
Copilot Evaluation
An Empirical Evaluation of GitHub Copilot’s Code Suggestions
HalluCode
Exploring and Evaluating Hallucinations in LLM-Powered Code Generation
CodeHalu
CodeHalu: Investigating Code Hallucinations in LLMs via Execution-based Verification
EffiBench
EffiBench: Benchmarking the Efficiency of Automatically Generated Code
Mercury
Mercury: A Code Efficiency Benchmark for Code Large Language Models
SStuBs
Large Language Models and Simple, Stupid Bugs
package hallucinations
We Have a Package for You! A Comprehensive Analysis of Package Hallucinations by Code Generating LLMs
HallTrigger
Code Hallucination
Large Language Models for Code
Large Language Models for Code: Security Hardening and Adversarial Testing
Purple Llama CYBERSECEVAL
Purple Llama CYBERSECEVAL: A Secure Coding Benchmark for Language Models
Lost at C
Lost at C: A User Study on the Security Implications of Large Language Model Code Assistants
AI Assistants Security
Do Users Write More Insecure Code with AI Assistants?
The Counterfeit Conundrum
The Counterfeit Conundrum: Can Code Language Models Grasp the Nuances of Their Incorrect Generations?
Bugs in LLM-generated Code
Bugs in Large Language Models Generated Code: An Empirical Stud
GitHub Copilot, Amazon CodeWhisperer, ChatGPT
Evaluating the Code Quality of AI-Assisted Code Generation Tools: An Empirical Study on GitHub Copilot, Amazon CodeWhisperer, and ChatGPT
ChatGPT Code Quality
No Need to Lift a Finger Anymore? Assessing the Quality of Code Generation by ChatGPT
CloudAPIBench
On Mitigating Code LLM Hallucinations with API Documentation
CodeMirage
CodeMirage: Hallucinations in Code Generated by Large Language Models
LLM-generated Code Efficiency
On Evaluating the Efficiency of Source Code Generated by LLMs
Syntactic Robustness
Syntactic Robustness for LLM-based Code Generation
DeSec
Decoding Secret Memorization in Code LLMs Through Token-Level Characterization
Bias Unveiled
Bias Unveiled: Investigating Social Bias in LLM-Generated Code
FairCoder
FairCoder: Evaluating Social Bias of LLMs in Code Generation
From Effectiveness to Efficiency
From Effectiveness to Efficiency: Comparative Evaluation of Code Generated by LCGMs for Bilingual Programming Questions
ENAMEL
How Efficient is LLM-Generated Code? A Rigorous & High-Standard Benchmark
DeVAIC
DeVAIC: A Tool for Security Assessment of AI-generated Code
PTMs
Comparing Robustness Against Adversarial Attacks in Code Generation: LLM-Generated vs. Human-Written
Codequal Analyzer
Improving LLM-Generated Code Quality with GRPO
Artificial-Intelligence Generated Code Considered Harmful
Artificial-Intelligence Generated Code Considered Harmful: A Road Map for Secure and High-Quality Code Generation
Unveiling Inefficiencies in LLM-Generated Code
Unveiling Inefficiencies in LLM-Generated Code: Toward a Comprehensive Taxonomy
Python Tests Quality
Quality Assessment of Python Tests Generated by Large Language Models
CoQuIR
CoQuIR: A Comprehensive Benchmark for Code Quality-Aware Information Retrieval
REAL
Training Language Models to Generate Quality Code with Program Analysis Feedback
CIDRe
CIDRe: A Reference-Free Multi-Aspect Criterion for Code Comment Quality Measurement
Infinite-Instruct
Infinite-Instruct: Synthesizing Scaling Code instruction Data with Bidirectional Synthesis and Static Verification
Quality In, Quality Out
Quality In, Quality Out: Investigating Training Data's Role in AI Code Generation
Security and Quality in LLM-Generated Code
Security and Quality in LLM-Generated Code: A Multi-Language, Multi-Model Analysis
SwallowCode
Rewriting Pre-Training Data Boosts LLM Performance in Math and Code
ROSE
ROSE: Transformer-Based Refactoring Recommendation for Architectural Smells
Refining ChatGPT-Generated Code
Refining ChatGPT-Generated Code: Characterizing and Mitigating Code Quality Issues
Qwen3
Qwen3 Technical Report
Qwen2.5
Qwen2.5 Technical Report
TeleChat
Technical Report of TeleChat2, TeleChat2.5 and T1
Kimi K2
Kimi K2: Open Agentic Intelligence
ReCode
ReCode: Updating Code API Knowledge with Reinforcement Learning
Seed-Coder
Seed-Coder: Let the Code Model Curate Data for Itself
Data-efficient Fine-tuning
Data-efficient LLM Fine-tuning for Code Generation
CRPE
CRPE: Expanding The Reasoning Capability of Large Language Model for Code Generation
DeepSeek-Coder
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
StarCoder 2 and The Stack v2
StarCoder 2 and The Stack v2: The Next Generation
CodeSmellEval
How Propense Are Large Language Models at Producing Code Smells? A Benchmarking Study
RPG
Rethinking Repetition Problems of LLMs in Code Generation
Repetition In Repetition Out
Repetition In Repetition Out: Towards Understanding Neural Text Degeneration from the Data Perspective
Every Sample Matters
Every Sample Matters: Leveraging Mixture-of-Experts and High-Quality Data for Efficient and Accurate Code LLM
WaveCoder
WaveCoder: Widespread And Versatile Enhancement For Code Large Language Models By Instruction Tuning
Brevity is the soul of wit
Brevity is the soul of wit: Pruning long files for code generation
Benchmark Builders
Large Language Models are Qualified Benchmark Builders: Rebuilding Pre-Training Datasets for Advancing Code Intelligence Tasks
Beyond Correctness
Beyond Correctness: Benchmarking Multi-dimensional Code Generation for Large Language Models
Generated Code Diversity
Is Functional Correctness Enough to Evaluate Code Language Models? Exploring Diversity of Generated Codes
CodeMI
Does Your Neural Code Completion Model Use My Code? A Membership Inference Approach
DataComp-LM
DataComp-LM: In search of the next generation of training sets for language models
Codex
Evaluating Large Language Models Trained on Code
Path Planning Evaluation
Assessing LLM code generation quality through path planning tasks
CODEJUDGE
CODEJUDGE : Evaluating Code Generation with Large Language Models
Datasets for Large Language Models
Datasets for Large Language Models: A Comprehensive Survey
Synthetic Data Generation
Synthetic Data Generation Using Large Language Models: Advances in Text and Code
Cracks in The Stack
Cracks in The Stack: Hidden Vulnerabilities and Licensing Risks in LLM Pre-Training Datasets
Unseen Horizons
Unseen Horizons: Unveiling the Real Capability of LLM Code Generation Beyond the Familiar
MG-Verilog
MG-Verilog: Multi-grained Dataset Towards Enhanced LLM-assisted Verilog Generation
Code Generation Survey
A Survey on Large Language Models for Code Generation
DataRecipe
DataRecipe --- How to Cook the Data for CodeLLM?
Training Data Extraction
Understanding Privacy Risks of Large Language Models in Japanese Based on Training Data Extraction Attacks
aiXcoder-7B
aiXcoder-7B: A Lightweight and Effective Large Language Model for Code Processing
Imperfect Code Generation
Imperfect Code Generation: Uncovering Weaknesses in Automatic Code Generation by Large Language Models
Inter-Dataset Code Duplication
On Inter-Dataset Code Duplication and Data Leakage in Large Language Models
LLM-ProS
LLM-ProS: Analyzing Large Language Models’ Performance in Competitive Problem Solving
ClassEval
Evaluating Large Language Models in Class-Level Code Generation
Uncovering Pretraining Code in LLMs
Uncovering Pretraining Code in LLMs: A Syntax-Aware Attribution Approach
RealSec-Bench
RealSec-bench: A Benchmark for Evaluating Secure Code Generation in Real-World Repositories
ShortCoder
ShortCoder: Knowledge-Augmented Syntax Optimization for Token-Efficient Code GenerationPreprint
APIKG4SYN
Framework-Aware Code Generation with API Knowledge Graph-Constructed Data: A Study on HarmonyOS
MultiCodeIF
A hierarchical and evolvable benchmark for fine-grained code instruction following with multi-turn feedback
Beyond Functional Correctness
Beyond functional correctness: Investigating coding style inconsistencies in large language models
Adadec
Adadec: Uncertainty-guided adaptive decoding for llm-based code generation
Code Copycat Conundrum
Code Copycat Conundrum: Demystifying Repetition in LLM-based Code Generation
AllianceCoder
What to retrieve for effective retrieval-augmented code generation? an empirical study and beyond
RustEvo^ 2
RustEvo^ 2: An Evolving Benchmark for API Evolution in LLM-based Rust Code Generation
RobGen
A Preliminary Study on the Robustness of Code Generation by Large Language Models
Llm Hallucinations in Practical Code Generation
Llm hallucinations in practical code generation: Phenomena, mechanism, and mitigation
COFFE
COFFE: A Code Efficiency Benchmark for Code Generation
AATK Benchmark
Asleep at the keyboard? assessing the security of github copilot's code contributions