🛠️ RQ5: Governance Strategies
We synthesize a Multi-layered Governance Framework spanning the data lifecycle and model inference stages.
💻 1. Code-Level Mitigation
- Model-level: SFT, RLHF/DPO, Reward-based optimization (execution correctness + static metrics).
- Generation-level:
- Pre-generation: Prompt Engineering, RAG, and Agent-based workflows.
- In-generation: Adaptive decoding constraints and Iterative Self-reflection.
- Post-generation: Automated AST-level repairs and sandbox execution filtering.

Fig. 8. Taxonomy of Code Issue Mitigation Strategies
📊 2. Data-Level Mitigation
- Cleaning & Filtering: Execution-feedback elimination and LLM-driven semantic cleaning.
- Data Balancing: Stratified resampling across languages and domains to mitigate bias.
- Data Enhancement: Refactoring, adding docstrings, and standardizing low-quality code.
- Data Augmentation: High-quality synthetic generation and integration of curated OS repos.
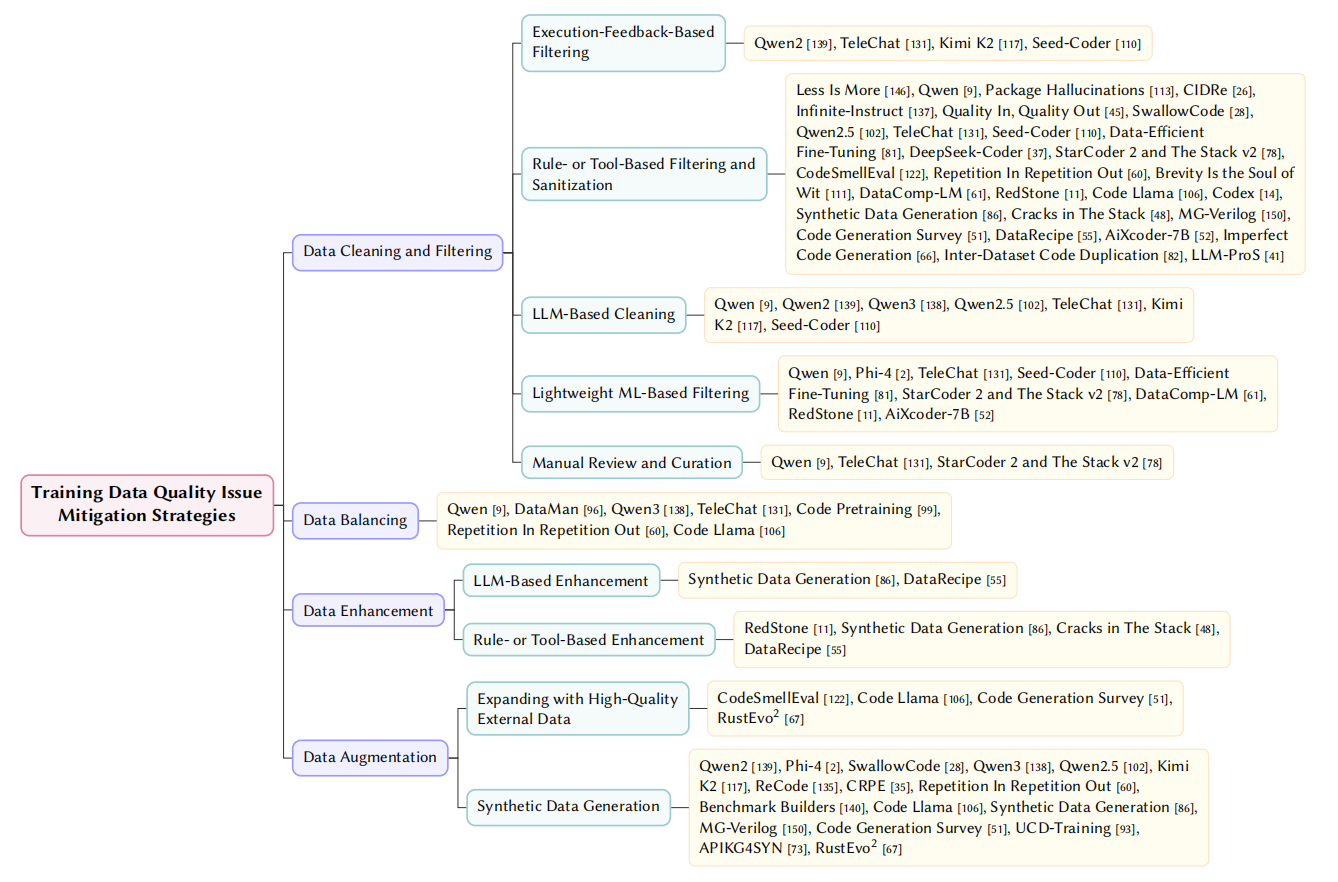
Fig. 9. Taxonomy of Training Data Issue Mitigation Strategies
📄 Referenced Papers
LLMs Meet Library Evolution
LLMs Meet Library Evolution: Evaluating Deprecated API Usage in LLM-based Code Completion
Less is More
Less is More: On the Importance of Data Quality for Unit Test Generation
Qwen
Qwen Technical Report
Qwen2
Qwen2 Technical Report
DataMan
DataMan: Data Manager for Pre-training Large Language Models
Phi-4
Phi-4 Technical Report
SStuBs
Large Language Models and Simple, Stupid Bugs
package hallucinations
We Have a Package for You! A Comprehensive Analysis of Package Hallucinations by Code Generating LLMs
Large Language Models for Code
Large Language Models for Code: Security Hardening and Adversarial Testing
CloudAPIBench
On Mitigating Code LLM Hallucinations with API Documentation
AutoAPIEval
A Comprehensive Framework for Evaluating API-oriented Code Generation in Large Language Models
Codequal Analyzer
Improving LLM-Generated Code Quality with GRPO
REAL
Training Language Models to Generate Quality Code with Program Analysis Feedback
CIDRe
CIDRe: A Reference-Free Multi-Aspect Criterion for Code Comment Quality Measurement
Infinite-Instruct
Infinite-Instruct: Synthesizing Scaling Code instruction Data with Bidirectional Synthesis and Static Verification
Quality In, Quality Out
Quality In, Quality Out: Investigating Training Data's Role in AI Code Generation
SwallowCode
Rewriting Pre-Training Data Boosts LLM Performance in Math and Code
Refining ChatGPT-Generated Code
Refining ChatGPT-Generated Code: Characterizing and Mitigating Code Quality Issues
Qwen3
Qwen3 Technical Report
Qwen2.5
Qwen2.5 Technical Report
TeleChat
Technical Report of TeleChat2, TeleChat2.5 and T1
Kimi K2
Kimi K2: Open Agentic Intelligence
ReCode
ReCode: Updating Code API Knowledge with Reinforcement Learning
Seed-Coder
Seed-Coder: Let the Code Model Curate Data for Itself
Data-efficient Fine-tuning
Data-efficient LLM Fine-tuning for Code Generation
CRPE
CRPE: Expanding The Reasoning Capability of Large Language Model for Code Generation
DeepSeek-Coder
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
Code Pretraining
How Does Code Pretraining Affect Language Model Task Performance?
StarCoder 2 and The Stack v2
StarCoder 2 and The Stack v2: The Next Generation
CodeSmellEval
How Propense Are Large Language Models at Producing Code Smells? A Benchmarking Study
RPG
Rethinking Repetition Problems of LLMs in Code Generation
Repetition In Repetition Out
Repetition In Repetition Out: Towards Understanding Neural Text Degeneration from the Data Perspective
Brevity is the soul of wit
Brevity is the soul of wit: Pruning long files for code generation
Benchmark Builders
Large Language Models are Qualified Benchmark Builders: Rebuilding Pre-Training Datasets for Advancing Code Intelligence Tasks
CodeCipher
CodeCipher: Learning to Obfuscate Source Code Against LLMs
DataComp-LM
DataComp-LM: In search of the next generation of training sets for language models
RedStone
RedStone: Curating General, Code, Math, and QA Data for Large Language Models
Code Llama
Code Llama: Open Foundation Models for Code
Codex
Evaluating Large Language Models Trained on Code
Path Planning Evaluation
Assessing LLM code generation quality through path planning tasks
CODEJUDGE
CODEJUDGE : Evaluating Code Generation with Large Language Models
Synthetic Data Generation
Synthetic Data Generation Using Large Language Models: Advances in Text and Code
Cracks in The Stack
Cracks in The Stack: Hidden Vulnerabilities and Licensing Risks in LLM Pre-Training Datasets
MG-Verilog
MG-Verilog: Multi-grained Dataset Towards Enhanced LLM-assisted Verilog Generation
Code Generation Survey
A Survey on Large Language Models for Code Generation
DataRecipe
DataRecipe --- How to Cook the Data for CodeLLM?
aiXcoder-7B
aiXcoder-7B: A Lightweight and Effective Large Language Model for Code Processing
Imperfect Code Generation
Imperfect Code Generation: Uncovering Weaknesses in Automatic Code Generation by Large Language Models
Inter-Dataset Code Duplication
On Inter-Dataset Code Duplication and Data Leakage in Large Language Models
LLM-ProS
LLM-ProS: Analyzing Large Language Models’ Performance in Competitive Problem Solving
UCD-Training
Unseen-Codebases-Domain Data Synthesis and Training Based on Code Graphs
ShortCoder
ShortCoder: Knowledge-Augmented Syntax Optimization for Token-Efficient Code GenerationPreprint
APIKG4SYN
Framework-Aware Code Generation with API Knowledge Graph-Constructed Data: A Study on HarmonyOS
MultiCodeIF
A hierarchical and evolvable benchmark for fine-grained code instruction following with multi-turn feedback
Beyond Functional Correctness
Beyond functional correctness: Investigating coding style inconsistencies in large language models
Adadec
Adadec: Uncertainty-guided adaptive decoding for llm-based code generation
Code Copycat Conundrum
Code Copycat Conundrum: Demystifying Repetition in LLM-based Code Generation
AllianceCoder
What to retrieve for effective retrieval-augmented code generation? an empirical study and beyond
RustEvo^ 2
RustEvo^ 2: An Evolving Benchmark for API Evolution in LLM-based Rust Code Generation
RobGen
A Preliminary Study on the Robustness of Code Generation by Large Language Models
Llm Hallucinations in Practical Code Generation
Llm hallucinations in practical code generation: Phenomena, mechanism, and mitigation
COFFE
COFFE: A Code Efficiency Benchmark for Code Generation