From Data to Code
Bridging Generation and Training: A Systematic Review of Quality Issues in LLMs for Code
A research map of how training data quality issues propagate into generated code defects, detection methods, and governance strategies across the LLM lifecycle.
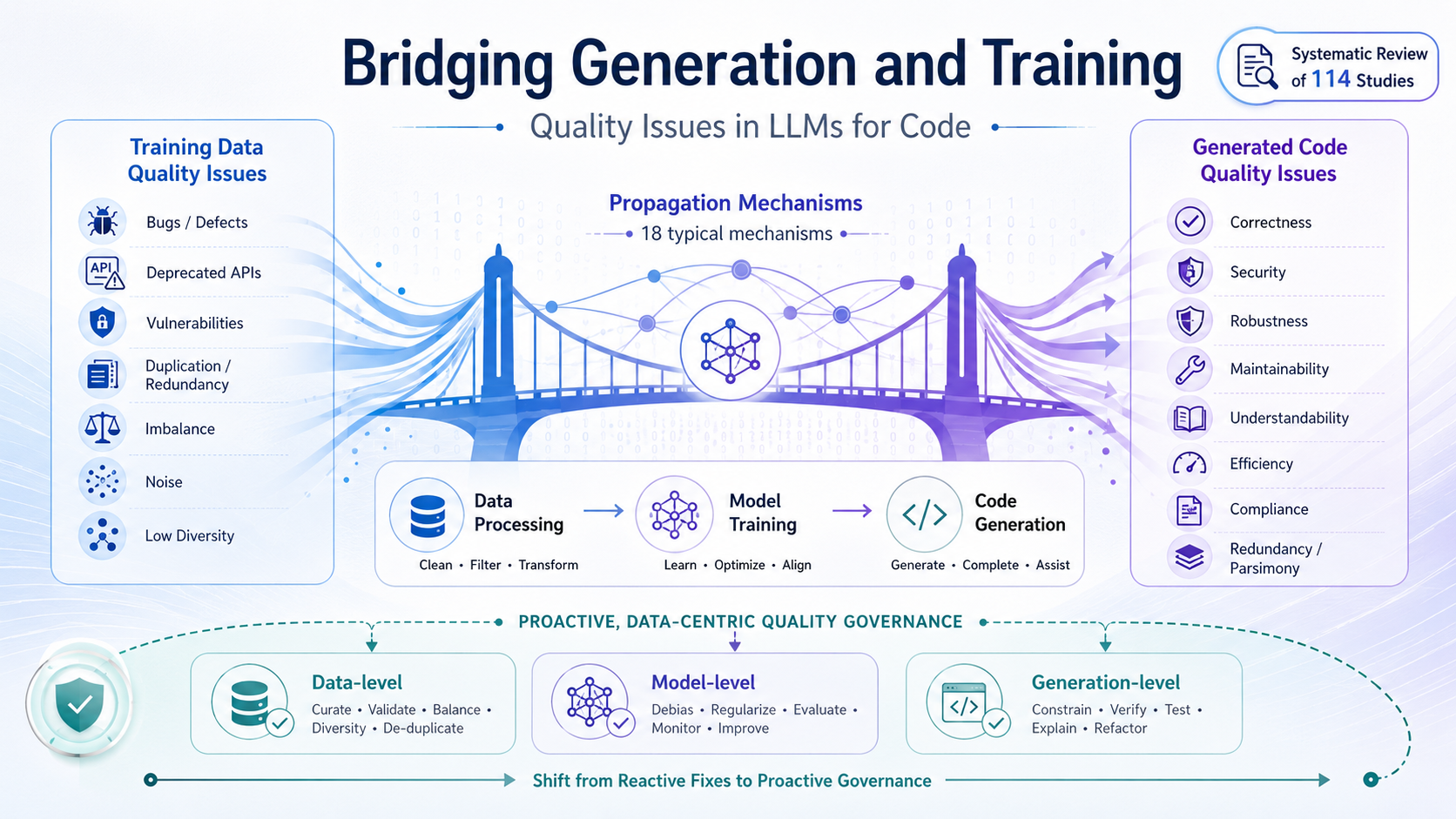
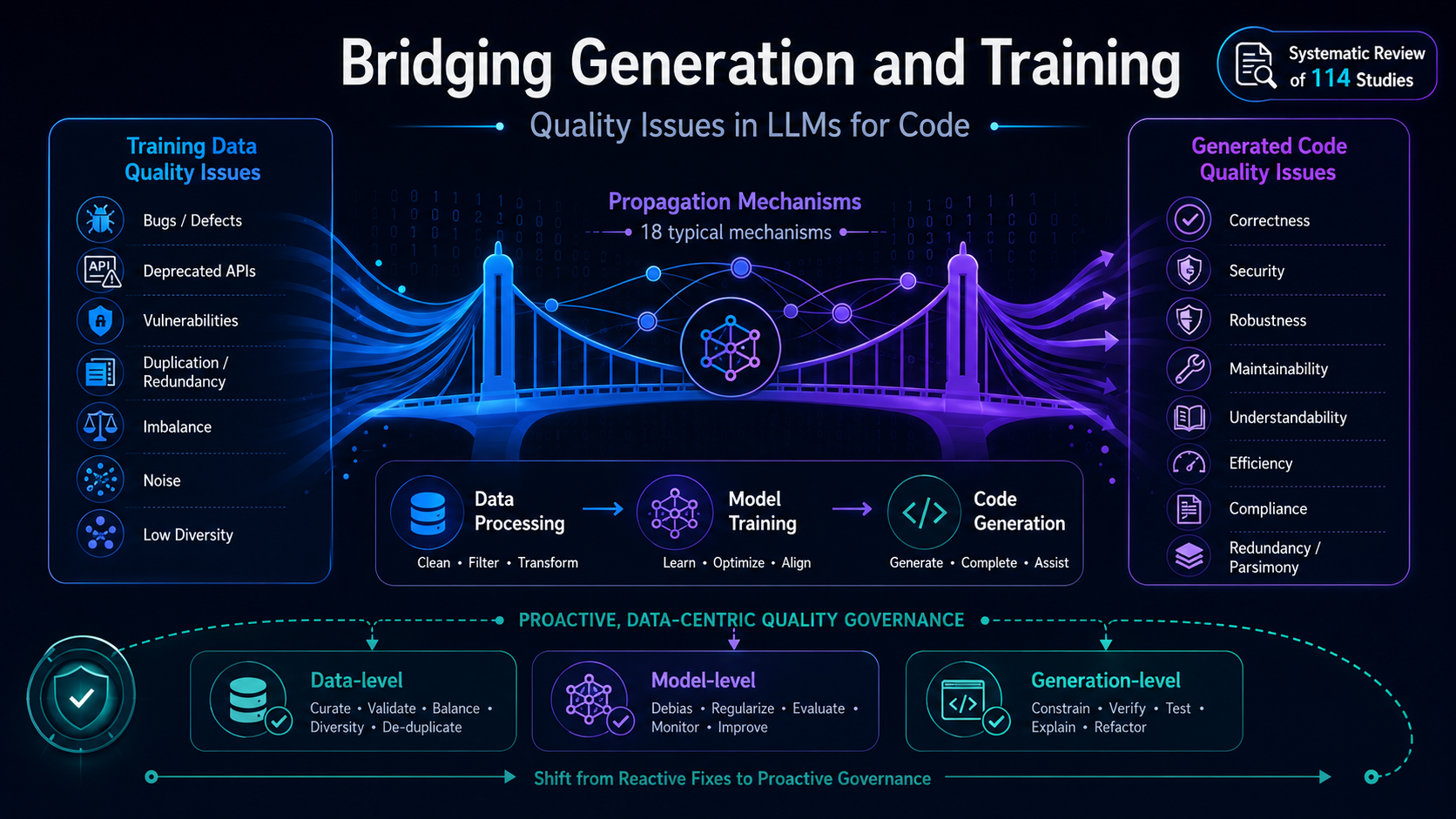
From Data to Code is the project website for Bridging Generation and Training: A Systematic Review of Quality Issues in LLMs for Code. This systematic literature review studies how training data quality issues in large language models for code propagate into generated code quality issues, including correctness bugs, security vulnerabilities, compliance risks, robustness failures, maintainability problems, and efficiency defects.
The review connects data defects, code generation failures, detection methods, and governance strategies across the LLM lifecycle. It provides a taxonomy of quality issues in LLM-generated code, a taxonomy of training data quality issues, and a mapping from data problems to code defects.
📢 News
- [2026-05] Our paper is now available on arXiv.
- [2026-04] The
From-Data-to-Coderepository is officially launched.
📖 Abstract
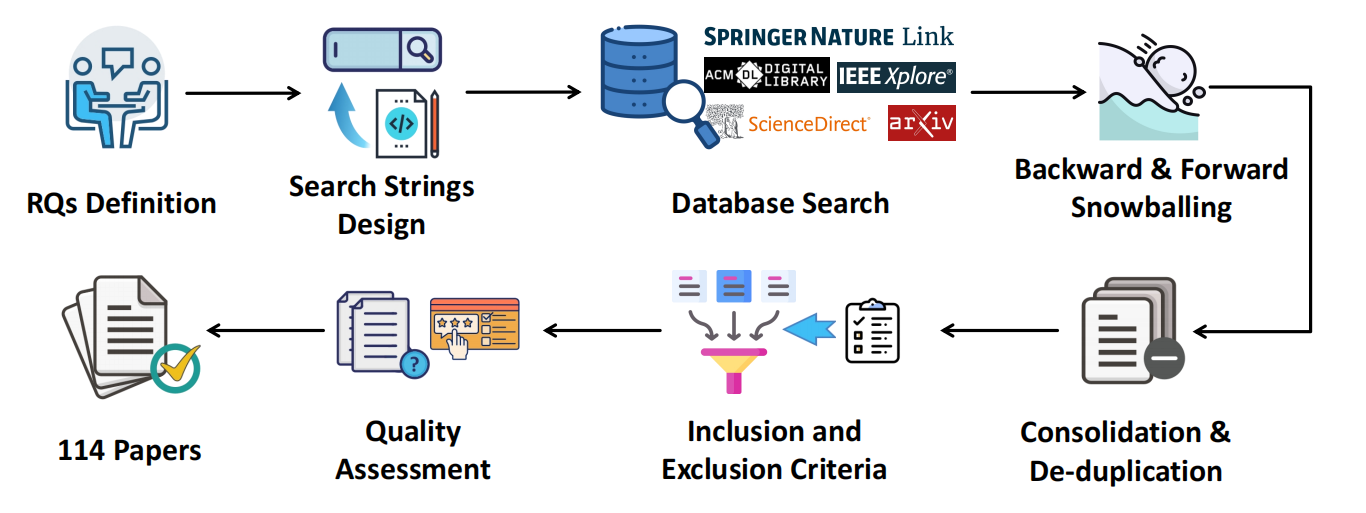
Fig. 1. Overview of the paper collection and filtering process.
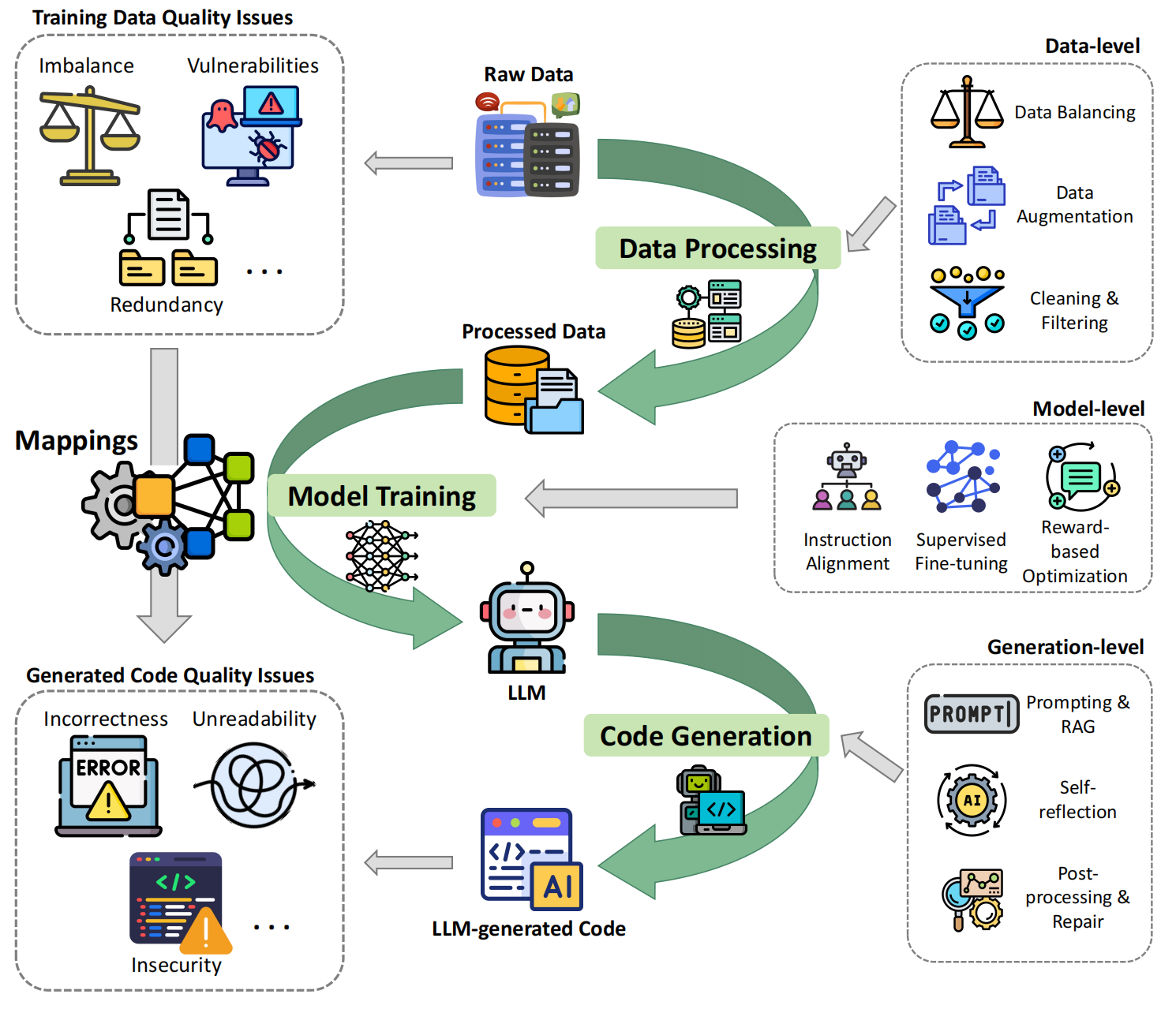
Fig. 2. Conceptual Framework of Quality Issues and Mitigation in the LLM Lifecycle.
🤝 Contribution
We welcome contributions from the community. If you have new research or have discovered missing classic papers, please follow these steps:
- Fork this repository.
- Add your paper to the corresponding RQ section.
- Submit a Pull Request.