Research
本页展示了实验室当前的研究工作,我们的研究方向聚焦于软件工程(SE)与人工智能(AI)交叉领域,主要探索AI4SE(AI赋能软件工程)和SE4AI(软件工程赋能AI)的前沿问题。具体研究包括:基于大模型的智能化开发与维护、软件开发知识图谱、大模型可信评测、可信代码大模型等。致力于利用大规模语言模型(LLM)、知识图谱(KG)等先进AI技术,解决软件工程中的核心挑战,并应对AI应用中的软件工程和系统工程问题。
相关链接请参考:
- GitHub: https://github.com/SYSUSELab/
- Hugging Face: https://huggingface.co/SYSUSELab
Highlighted
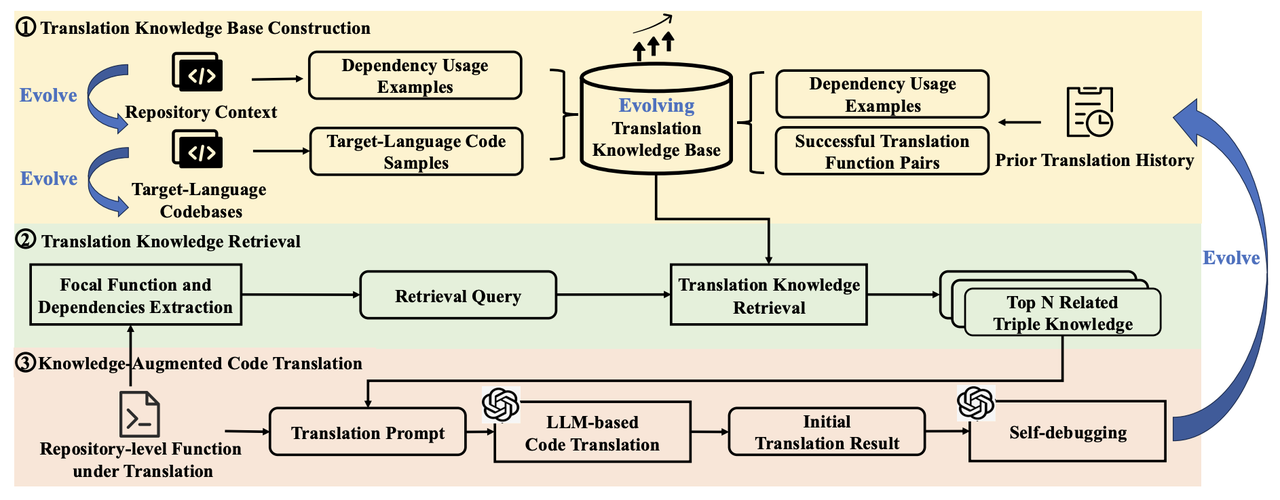
Enhancing LLM-based Code Translation in Repository Context via Triple Knowledge-Augmented
arXiv
·
28 Mar 2025
·
arxiv:2503.18305
本文提出了 K3Trans 模型,一种利用三重知识增强的大语言模型,用于在代码仓库上下文中进行代码翻译。
All
Enhancing LLM-based Code Translation in Repository Context via Triple Knowledge-Augmented
arXiv
·
28 Mar 2025
·
arxiv:2503.18305
本文提出了 K3Trans 模型,一种利用三重知识增强的大语言模型,用于在代码仓库上下文中进行代码翻译。
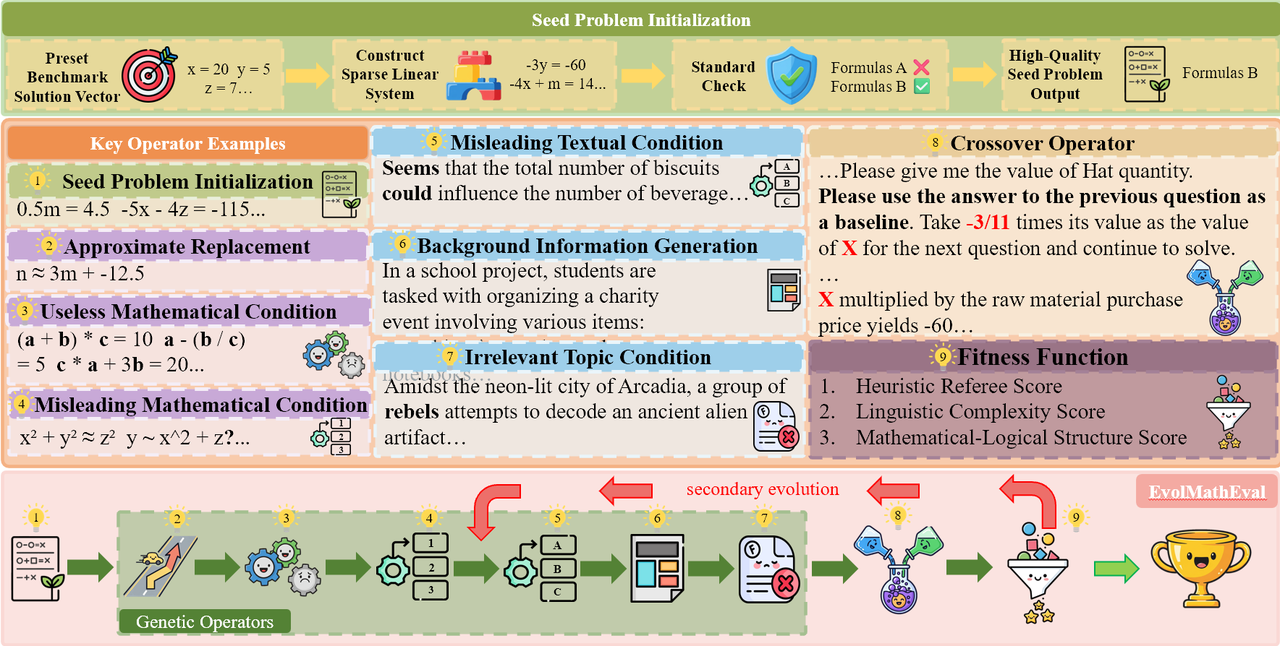
EvolMathEval: Towards Evolvable Benchmarks for Mathematical Reasoning via Evolutionary Testing
arXiv
·
19 Aug 2025
·
arxiv:2508.13003
本文介绍了 EvolMathEval,一个通过演化测试(Evolutionary Testing)为大模型的数学推理能力构建可演化基准测试的方法。
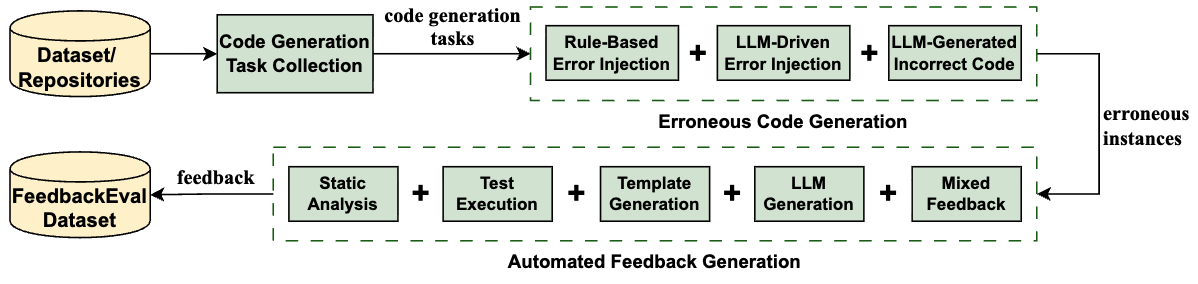
FeedbackEval: A Benchmark for Evaluating Large Language Models in Feedback-Driven Code Repair Tasks
arXiv
·
10 Apr 2025
·
arxiv:2504.06939
本文提出了 FeedbackEval,一个用于在反馈驱动的代码修复场景下评估大型语言模型的基准测试。
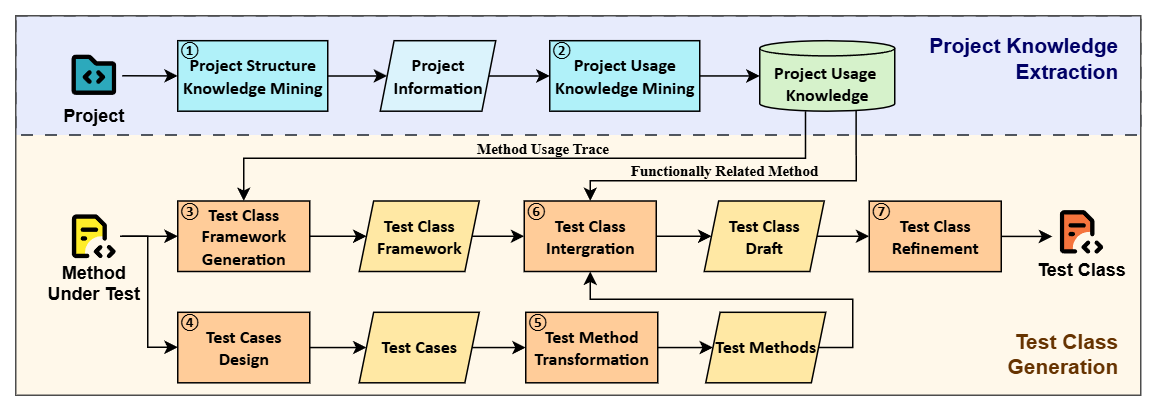
KTester: Injecting Project and Testing Knowledge into LLM-based Unit Test Generation
[no publisher info]
·
01 Jan 2025
·
[no id info]
本文介绍了 KTester,一种将项目和测试知识注入到基于大语言模型的单元测试生成中的方法。

Repository-level Code Translation Benchmark Targeting Rust
arXiv
·
28 Mar 2025
·
arxiv:2411.13990
本文提出了一个针对 Rust 语言的仓库级代码翻译基准测试,关注增量翻译和仓库级上下文。
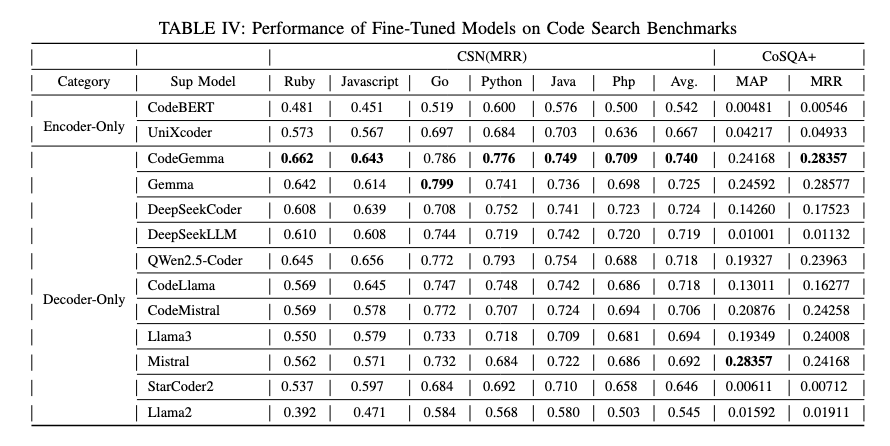
Are Decoder-Only Large Language Models the Silver Bullet for Code Search?
arXiv
·
03 Sep 2025
·
arxiv:2410.22240
本文探讨了仅解码器(Decoder-Only)架构的大语言模型在代码搜索任务中的有效性及其是否为终极解决方案。